 Bytes cortos: El rastreador web es un programa que navega por Internet (World Wide Web) de una manera predeterminada, configurable y automatizada y realiza una determinada acción en el contenido rastreado. Los motores de búsqueda como Google y Yahoo utilizan las arañas como un medio para proporcionar datos actualizados..
Bytes cortos: El rastreador web es un programa que navega por Internet (World Wide Web) de una manera predeterminada, configurable y automatizada y realiza una determinada acción en el contenido rastreado. Los motores de búsqueda como Google y Yahoo utilizan las arañas como un medio para proporcionar datos actualizados..
Webhose.io, una compañía que brinda acceso directo a datos en vivo de cientos de miles de foros, noticias y blogs, publicó el 12 de agosto de 2015 los artículos que describen un pequeño rastreador web de múltiples subprocesos escrito en Python. Este rastreador web de Python es capaz de rastrear toda la web por usted. Ran Geva, el autor de este pequeño rastreador web de Python dice que:
Escribí como "Sucio", "Iffy", "Malo", "No muy bueno". Digo, hace el trabajo y descarga miles de páginas de varias páginas en cuestión de horas. No se requiere configuración, no hay importaciones externas, simplemente ejecute el siguiente código de Python con un sitio de semillas y siéntese (o haga otra cosa porque podría tomar algunas horas o días, dependiendo de la cantidad de datos que necesite).El rastreador multiproceso basado en Python es bastante simple y muy rápido. Es capaz de detectar y eliminar enlaces duplicados y guardar tanto la fuente como el enlace que luego se pueden usar para encontrar enlaces entrantes y salientes para calcular el rango de la página. Es completamente gratuito y el código se enumera a continuación:
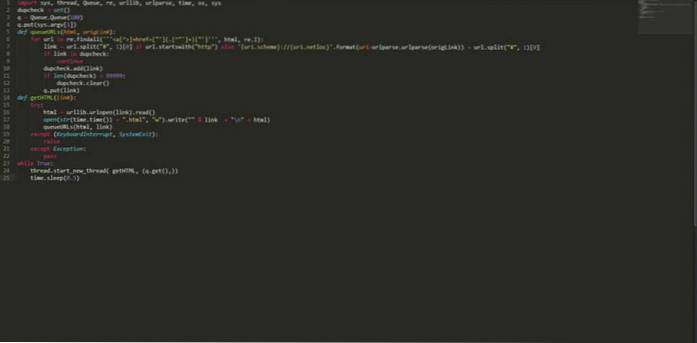
import sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): para URL en re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] if url.startswith ( "http") else 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] si el enlace está en dupcheck : continúe dupcheck.add (enlace) si len (dupcheck)> 99999: dupcheck.clear () q.put (enlace) def getHTML (enlace): intente: html = urllib.urlopen (enlace) .read () abrir (str (time.time ()) + ".html", "w"). write (""% link + "\ n" + html) queueURLs (html, link) excepto (KeyboardInterrupt, SystemSalir): subir excepto Exception: pass while True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Guarde el código anterior con algún nombre, digamos "myPythonCrawler.py". Para comenzar a rastrear cualquier sitio web, simplemente escriba:
$ python myPythonCrawler.py https://fossbytes.com
Siéntese y disfrute de este rastreador web en Python. Descargará todo el sitio por ti..
Conviértete en un profesional de Python con estos cursos
¿Te gusta este rastreador web multiproceso basado en Python simple y muerto? Háganos saber en los comentarios.
Leer también: Cómo crear un USB de arranque sin ningún software en Windows 10